There are many different types of machine learning algorithms, and the best algorithm for a particular problem will depend on the specific characteristics of the data and the desired outcome. Some common types of machine learning algorithms include:
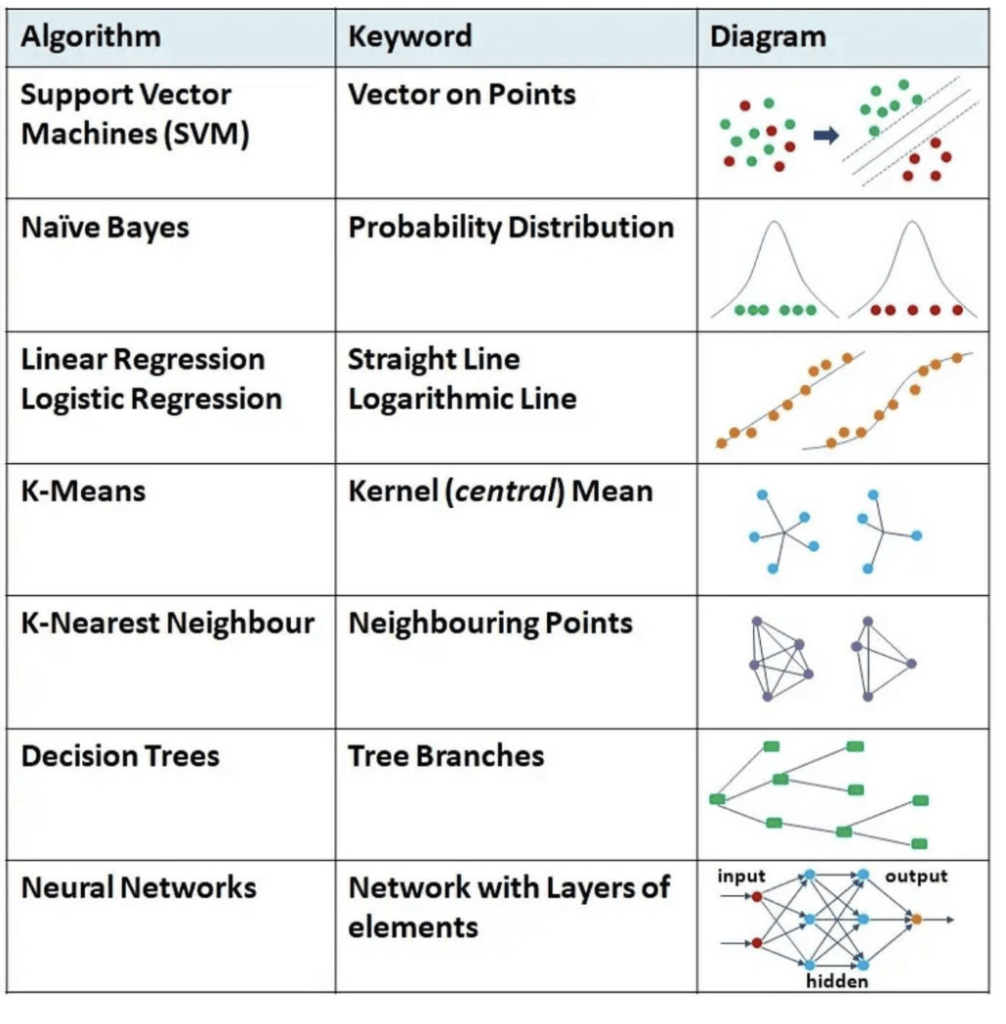
- Linear regression: Linear regression is a simple machine learning algorithm that is used to model the relationship between a dependent variable and one or more independent variables. It is commonly used to predict a continuous numerical outcome based on a set of input features.
- Logistic regression: Logistic regression is a type of regression analysis that is used to predict a binary outcome (i.e., a outcome that can only have two possible values, such as “yes” or “no”). It is a widely used method for classification tasks, such as predicting whether a customer will churn or not.
- Decision trees: Decision trees are a type of machine learning algorithm that are used to model the decision-making process. They consist of a series of decision nodes, where each node represents a decision point, and leaf nodes, where the final decision is made. Decision trees are often used for classification tasks, such as determining whether a customer will churn or not.
- Random forests: Random forests are a type of ensemble learning algorithm that combines multiple decision trees to make a prediction. Each tree in the ensemble is trained on a different subset of the data, and the final prediction is made by averaging the predictions of all the trees. Random forests are often used for regression and classification tasks.
- K-means clustering: K-means clustering is a type of unsupervised machine learning algorithm that is used to group data points into clusters based on their similarity. It is commonly used for clustering tasks, such as customer segmentation or anomaly detection.
- Naive Bayes is a type of machine learning algorithm that is based on the Bayes theorem of probability. It is called “naive” because it makes the assumption that all the features in the data are independent of each other, which is often not the case in real-world data. Despite this assumption, Naive Bayes algorithms can still perform well in many situations and are widely used for classification tasks.
- Support Vector Machines (SVMs) are a type of supervised learning algorithm that can be used for classification or regression tasks. The idea behind SVMs is to find the hyperplane in a high-dimensional space that maximally separates the different classes. Once this hyperplane is found, new data can be easily classified by assigning them to the side of the hyperplane on which they fall.
- A neural network is a type of machine learning algorithm modeled after the structure and function of the human brain. It is composed of multiple layers of interconnected “neurons,” which process and transmit information. Neural networks are trained using large amounts of data and are able to learn and make predictions or decisions based on that data. They are commonly used in a variety of applications, such as image recognition, natural language processing, and time series forecasting.
These are just a few examples of common machine learning algorithms. There are many other algorithms that are used in different situations and for different types of problems.