
As I mentioned in my previous blog, face mask detection uses deep learning techniques. In this blog, you will learn how to accurately detect the face mask and classify it into two categories (face mask and no face mask).
For this purpose, first, we trained the deep learning CNN model (MOBILE NET) using the facemask dataset. After training the model, we used that model with the help of OpenCV to predict facemasks in real time. The Project is divided into two parts
- Model Training using MobileNet-based CNN model
- Realtime Prediction using Tkinter GUI
Click to download Dataset:
Hey folks, You can download the whole project , link is mention at the bottom of this blogs
Project link below
Model Training
from enum import Enum
import os
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from tensorflow.keras.preprocessing.image import load_img
from tensorflow.keras.preprocessing.image import img_to_array
import numpy as np
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import ImageDataGenerator
class CNN_TYPE(Enum):
VGGNET = 1
GOOGLENET = 2
RESNET = 3
MOBILENET = 4
current_cnn_type = CNN_TYPE.MOBILENET
current_cnn_type
def get_cnn_mode(type, image_shape):
preprocess_input = []
abc_model = []
t2wi_model = []
if type==CNN_TYPE.VGGNET:
preprocess_input = tf.keras.applications.vgg16.preprocess_input
model = tf.keras.applications.VGG16(input_shape=image_shape,
include_top=False,
weights='imagenet')
elif type==CNN_TYPE.GOOGLENET:
preprocess_input = tf.keras.applications.inception_v3.preprocess_input
model = tf.keras.applications.InceptionV3(input_shape=image_shape,
include_top=False,
weights='imagenet')
elif type==CNN_TYPE.RESNET:
preprocess_input = tf.keras.applications.resnet50.preprocess_input
model = tf.keras.applications.ResNet50(input_shape=image_shape,
include_top=False,
weights='imagenet')
elif type==CNN_TYPE.MOBILENET:
preprocess_input = tf.keras.applications.mobilenet_v2.preprocess_input
model = tf.keras.applications.MobileNetV2(input_shape=image_shape,
include_top=False,
weights='imagenet')
else:
preprocess_input = tf.keras.applications.vgg19.preprocess_input
model = tf.keras.applications.MobileNetV2(input_shape=image_shape,
include_top=False,
weights='imagenet')
return preprocess_input, model
IMG_SHAPE = (224, 224, 3)
preprocess_input, base_model = get_cnn_mode(current_cnn_type, IMG_SHAPE)
# initialize the initial learning rate, number of epochs to train for,
# and batch size
LR = 1e-4
EPOCHS = 100
batch_size = 32
InputPath = "/content/drive/MyDrive/Datasets_everyone/FaceMask_Dataset"
Clasess = ["WithMask", "WithoutMask"]
# grab the list of images in our dataset directory, then initialize
# the list of data (i.e., images) and class images
print("[INFO] loading images...")
images = []
labels = []
for each_cls in Clasess:
path = os.path.join(InputPath, each_cls)
for img in os.listdir(path):
img_path = os.path.join(path, img)
image = load_img(img_path, target_size=(224, 224))
image = img_to_array(image)
image = preprocess_input(image)
images.append(image)
labels.append(each_cls)
# perform one-hot encoding on the labels
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
labels = to_categorical(labels)
images = np.array(images, dtype="float32")
labels = np.array(labels)
(X_train, X_test, Y_train, Y_test) = train_test_split(images, labels,test_size=0.20, stratify=labels, random_state=42)
# construct the training image generator for data augmentation
data_augumentation = ImageDataGenerator(
rotation_range=20,
zoom_range=0.15,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.15,
horizontal_flip=True,
fill_mode="nearest")
# construct the head of the model that will be placed on top of the
# the base model
model = base_model.output
#model = AveragePooling2D(pool_size=(7, 7))(model)
model=tf.keras.layers.GlobalAveragePooling2D()(model)
model = Flatten(name="flatten")(model)
model = Dense(128, activation="relu")(model)
model = Dropout(0.5)(model)
model = Dense(2, activation="softmax")(model)history = model.fit(data_augumentation.flow(X_train, Y_train, batch_size=batch_size),steps_per_epoch=len(X_train) // batch_size,validation_data=(X_test, Y_test),
validation_steps=len(X_test) // batch_size,
epochs=EPOCHS)
model = Model(inputs=base_model.input, outputs=model)
for layer in base_model.layers:
layer.trainable = False
# compile our model
opt = tf.keras.optimizers.Adam(lr=LR, decay=LR / EPOCHS)
model.compile(loss="binary_crossentropy", optimizer=opt,metrics=["accuracy"])
model.summary()
history = model.fit(data_augumentation.flow(X_train, Y_train, batch_size=batch_size),steps_per_epoch=len(X_train) // batch_size,validation_data=(X_test, Y_test),
validation_steps=len(X_test) // batch_size,
epochs=EPOCHS)
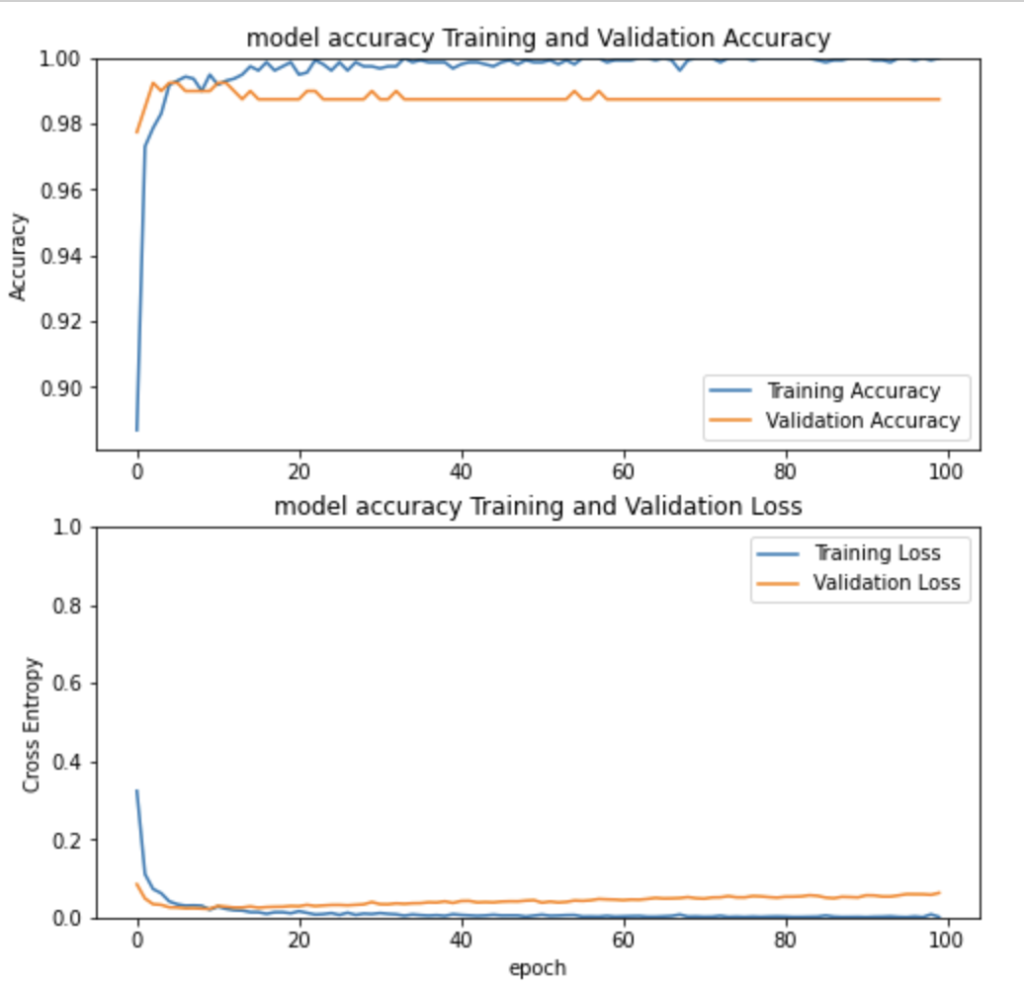
import matplotlib.pyplot as plt
def train_histor_view(history, name):
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label= 'Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title(name + ' ' + 'Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title(name + ' ' + 'Training and Validation Loss')
plt.xlabel('epoch')
plt.show()
train_histor_view(history, 'model accuracy')
from sklearn.metrics import classification_report
# make predictions on the testing set
print("[INFO] evaluating network...")
predIdxs = model.predict(X_test, batch_size=batch_size)
# for each image in the testing set we need to find the index of the
# label with corresponding largest predicted probability
predIdxs = np.argmax(predIdxs, axis=1)
# show a nicely formatted classification report
print(classification_report(Y_test.argmax(axis=1), predIdxs,target_names=lb.classes_))
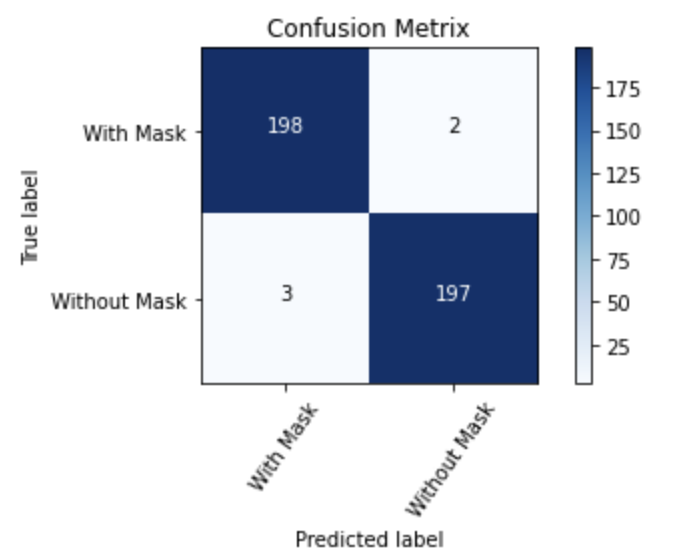
from sklearn.metrics import confusion_matrix
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
print(cm)
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=55)
plt.yticks(tick_marks, classes)
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
cm = confusion_matrix(Y_test.argmax(axis=1), predIdxs)
cm_plot_label =['With Mask', 'Without Mask']
plot_confusion_matrix(cm, cm_plot_label, title ='Confusion Metrix')
def calculate_sensitivity_specificity(y_test, y_pred_test):
# Note: More parameters are defined than necessary.
# This would allow return of other measures other than sensitivity and specificity
# Get true/false for whether a breach actually occurred
actual_pos = y_test == 1
actual_neg = y_test == 0
# Get true and false test (true test match actual, false tests differ from actual)
true_pos = (y_pred_test == 1) & (actual_pos)
false_pos = (y_pred_test == 1) & (actual_neg)
true_neg = (y_pred_test == 0) & (actual_neg)
false_neg = (y_pred_test == 0) & (actual_pos)
# Calculate accuracy
accuracy = np.mean(y_pred_test == y_test)
# Calculate sensitivity and specificity
sensitivity = np.sum(true_pos) / np.sum(actual_pos)
specificity = np.sum(true_neg) / np.sum(actual_neg)
return sensitivity, specificity, accuracy
sensitivity, specificity, accuracy = calculate_sensitivity_specificity(Y_test.argmax(axis=1), predIdxs)
print ('Sensitivity:', sensitivity)
print ('Specificity:', specificity)
print ('Accuracy:', accuracy)
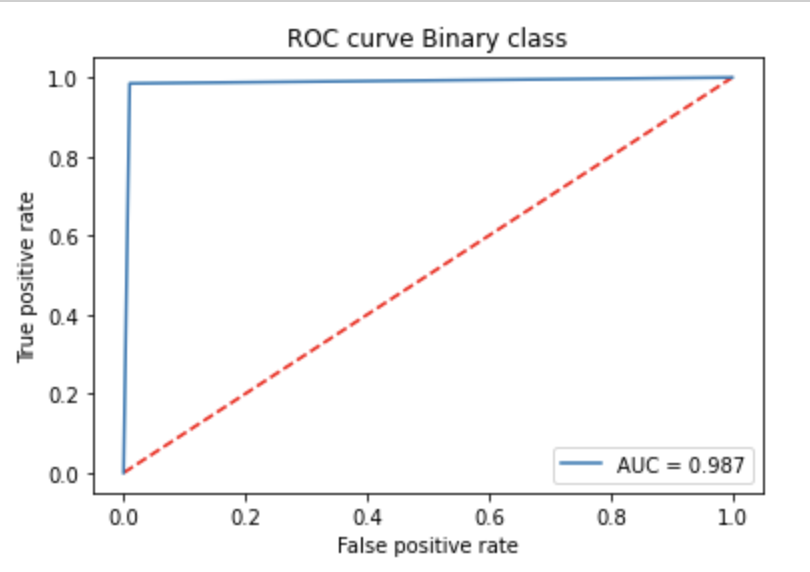
from sklearn.metrics import roc_auc_score, auc
from sklearn.metrics import roc_curve
roc_log = roc_auc_score(Y_test.argmax(axis=1), predIdxs)
false_positive_rate, true_positive_rate, threshold = roc_curve(Y_test.argmax(axis=1), predIdxs)
area_under_curve = auc(false_positive_rate, true_positive_rate)
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(false_positive_rate, true_positive_rate, label='AUC = {:.3f}'.format(area_under_curve))
plt.xlabel('False positive rate')
plt.ylabel('True positive rate')
plt.title('ROC curve Binary class')
plt.legend(loc='best')
plt.show()
#plt.savefig(ROC_PLOT_FILE, bbox_inches='tight')
plt.close()
# saving and loading the .h5 model
# save model
model.save('MobileNet.h5')
print('Model Saved!')
Load Model:
from tensorflow.keras.models import load_model
# load model
savedModel=load_model('MobileNet.h5')
savedModel.summary()
Realtime Facemask Detection Code:
#!/usr/bin/env python
# coding: utf-8
import os
import cv2
import imutils
import time
import numpy as np
from tensorflow.keras.preprocessing.image import img_to_array
from tensorflow.keras.models import load_model
from tensorflow.keras.applications.mobilenet_v2 import preprocess_input
from imutils.video import VideoStream
import tkinter as tk
from tkinter import filedialog
from tkinter import *
import math
import argparse
################
txt_file_path ="face_detector/deploy.prototxt"
caffemodel_weights_Path = "face_detector/res10_300x300_ssd_iter_140000.caffemodel"
Pretrain_face_detection_Model = cv2.dnn.readNet(txt_file_path, caffemodel_weights_Path)
# Our trained model for classification of mask and without mask
cls_model = load_model("MobileNet.h5")
import cv2
import math
import argparse
def highlightFace(net, frame, conf_threshold=0.7):
frameOpencvDnn=frame.copy()
frameHeight=frameOpencvDnn.shape[0]
frameWidth=frameOpencvDnn.shape[1]
blob=cv2.dnn.blobFromImage(frameOpencvDnn, 1.0, (300, 300), [104, 117, 123], True, False)
net.setInput(blob)
detections=net.forward()
faceBoxes=[]
for i in range(detections.shape[2]):
confidence=detections[0,0,i,2]
if confidence>conf_threshold:
x1=int(detections[0,0,i,3]*frameWidth)
y1=int(detections[0,0,i,4]*frameHeight)
x2=int(detections[0,0,i,5]*frameWidth)
y2=int(detections[0,0,i,6]*frameHeight)
faceBoxes.append([x1,y1,x2,y2])
cv2.rectangle(frameOpencvDnn, (x1,y1), (x2,y2), (0,255,0), int(round(frameHeight/150)), 8)
return frameOpencvDnn,faceBoxes
faceProto="gad/opencv_face_detector.pbtxt"
faceModel="gad/opencv_face_detector_uint8.pb"
ageProto="gad/age_deploy.prototxt"
ageModel="gad/age_net.caffemodel"
genderProto="gad/gender_deploy.prototxt"
genderModel="gad/gender_net.caffemodel"
MODEL_MEAN_VALUES=(78.4263377603, 87.7689143744, 114.895847746)
ageList=['(0-2)', '(4-6)', '(8-12)', '(15-20)', '(25-32)', '(38-43)', '(48-53)', '(60-100)']
genderList=['Male','Female']
faceNet=cv2.dnn.readNet(faceModel,faceProto)
ageNet=cv2.dnn.readNet(ageModel,ageProto)
genderNet=cv2.dnn.readNet(genderModel,genderProto)
def main_func(vid_path=''):
################
def Realtime_Detection_func(Video_frame, Pretrain_face_detection_Model,cls_model):
(height, width) = Video_frame.shape[:-1]
Img_blob = cv2.dnn.blobFromImage(Video_frame, 1.0, (224, 224),(104.0, 177.0, 123.0))
# pass the blob through the network and obtain the face detections
Pretrain_face_detection_Model.setInput(Img_blob)
face_identify = Pretrain_face_detection_Model.forward()
print(face_identify.shape)
# initialize our list of faces, their corresponding locations,
# and the list of predictions from our face mask network
faces_in_frame_lst = []
faces_location_lst = []
model_preds_lst = []
for i in range(0, face_identify.shape[2]):
conf_value = face_identify[0, 0, i, 2]
if conf_value > 0.6:
Rectangle_box = face_identify[0, 0, i, 3:7] * np.array([width, height, width, height])
(starting_PointX, starting_PointY, ending_PointX, ending_PointY) = Rectangle_box.astype("int")
(starting_PointX, starting_PointY) = (max(0, starting_PointX), max(0, starting_PointY))
(ending_PointX, ending_PointY) = (min(width - 1, ending_PointX), min(height - 1, ending_PointY))
face_detect = vid_frm[starting_PointY:ending_PointY, starting_PointX:ending_PointX]
face_RGB = cv2.cvtColor(face_detect, cv2.COLOR_BGR2RGB)
face_Resize = cv2.resize(face_RGB, (224, 224))
face_to_array = img_to_array(face_Resize)
face_rescale = preprocess_input(face_to_array)
faces_in_frame_lst.append(face_rescale)
faces_location_lst.append((starting_PointX, starting_PointY, ending_PointX, ending_PointY))
if len(faces_in_frame_lst) > 0:
faces_in_frame_lst = np.array(faces_in_frame_lst, dtype="float32")
model_preds_lst = cls_model.predict(faces_in_frame_lst, batch_size=16)
return (model_preds_lst, faces_location_lst)
# loop over the frames from the video stream
if vid_path != '':
print("[INFO] starting video stream...")
#vid_stm = VideoStream(src=vid_path).start()
vid_stm = FileVideoStream(src=vid_path).start()
elif vid_path == '':
print("[INFO] starting live stream...")
vid_stm = VideoStream(src=0).start()
while True:
vid_frm = vid_stm.read()
vid_frm = imutils.resize(vid_frm, width=800)
#=====
padding=20
resultImg,faceBoxes=highlightFace(faceNet,vid_frm)
if not faceBoxes:
print("No face detected")
(model_preds_lst, faces_location_lst) = Realtime_Detection_func(vid_frm, Pretrain_face_detection_Model, cls_model)
for (pred,Rectangle_box,faceBox) in zip(model_preds_lst, faces_location_lst,faceBoxes):
(starting_PointX, starting_PointY, ending_PointX, ending_PointY) = Rectangle_box
(mask_img, NoMask_img) = pred
face=vid_frm[max(0,faceBox[1]-padding):
min(faceBox[3]+padding,vid_frm.shape[0]-1),max(0,faceBox[0]-padding)
:min(faceBox[2]+padding, vid_frm.shape[1]-1)]
blob=cv2.dnn.blobFromImage(face, 1.0, (227,227), MODEL_MEAN_VALUES, swapRB=False)
genderNet.setInput(blob)
genderPreds=genderNet.forward()
gender=genderList[genderPreds[0].argmax()]
print(f'Gender: {gender}')
ageNet.setInput(blob)
agePreds=ageNet.forward()
age=ageList[agePreds[0].argmax()]
print(f'Age: {age[1:-1]} years')
label = "Mask" if mask_img > NoMask_img else "No Mask"
color = (0, 255, 0) if label == "Mask" else (0, 0, 255)
#label = "{}: {:.2f}%".format(label, max(mask_img, NoMask_img) * 100)
cv2.putText(vid_frm, label+':'+f' {gender}, {age}', (starting_PointX, starting_PointY - 10),cv2.FONT_HERSHEY_SIMPLEX, 0.45, color, 2)
cv2.rectangle(vid_frm, (starting_PointX, starting_PointY), (ending_PointX, ending_PointY), color, 2)
cv2.imshow("Video Frame", vid_frm)
key = cv2.waitKey(1) & 0xFF
if key == ord("q"):
break
# do a bit of cleanup
cv2.destroyAllWindows()
vid_stm.stop()
def exit():
#window.destroy()
window.quit()
def main():
# Function for opening the
# file explorer window
def browseFiles():
filename = filedialog.askopenfilename(initialdir = "/",
title = "Select a File",
filetypes = (("Text files",
"*.mp4"),
("all files",
"*.*")))
# Change label contents
label_file_explorer.configure(text="File Opened: "+filename)
return(filename)
# Create the root window
window = Tk()
# Set window title
window.title('Face Mask Detection')
# Set window size
window.geometry("500x500")
#Set window background color
window.config(background = "white")
# # Create a File Explorer label
label_file_explorer = Label(window,
text = "Face mask Detection using Tkinter",
width = 100, height = 4,
fg = "blue")
button_explore = Button(window,
text = "Browse Files",
command = browseFiles)
button_live_stream=Button(window,
text = "Live Stream",
command = main_func)
button_video_stream=Button(window,
text = "Video Stream",
command = lambda: main_func(browseFiles()))
button_exit = Button(window,
text = "Exit",
command = exit)
button_live_stream.grid(column = 1,row = 4)
button_video_stream.grid(column = 1,row = 5)
button_exit.grid(column = 1,row = 6)
# Let the window wait for any events
window.mainloop()
if __name__ =="__main__":
main()