
Self-Supervised Learning (Self-Supervised Learning) is a new paradigm between unsupervised and supervised learning, which aims to reduce the challenging demand for large amounts of annotated data. It provides some kind of supervision signals for feature learning by defining annotation-free pretext tasks.
The term self-supervised learning (SSL) has been used (sometimes differently) in different contexts and fields, such as representation learning [1], neural networks, robotics [2], natural language processing, and reinforcement learning. In all cases, the basic idea is to automatically generate some kind of supervisory signal to solve some task (typically, to learn representations of the data or to automatically label a dataset).
I will describe what SSL means more specifically in three contexts: representation learning, neural networks and robotics.
Representation learning
The term self-supervised learning has been widely used to refer to techniques that do not use human-annotated datasets to learn (visual) representations of the data (i.e. representation learning).
With self-supervised training, we can pre-train models on incredibly large databases without worrying about human labels.

Large-scale labelled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications. To avoid the extensive cost of collecting and annotating large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels.
What is Self-Supervised learning?
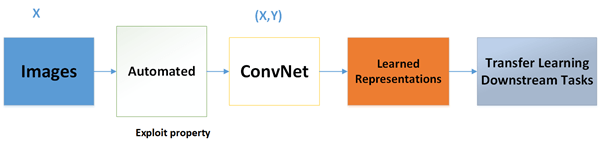
Self-supervised learning is a subset of unsupervised learning methods. Self-supervised learning refers to learning methods in which ConvNets are explicitly trained with automatically generated labels. This review only focuses on self-supervised learning methods for visual feature learning with ConvNets in which the features can be transferred to multiple different computer vision tasks. Since no human annotations are needed to generate pseudo labels during self-supervised training, very largescale datasets can be used for self-supervised training. Trained with these pseudo labels, self-supervised methods achieved promising results and the gap with supervised methods in performance on downstream tasks becomes smaller.
Simple ways we can says
Self-supervised learning is a relatively recent learning technique where the training data is autonomously (or automatically) labeled. It is still supervised learning, but the datasets do not need to be manually labeled by a human, but they can e.g. be labelled by finding and exploiting the relations (or correlations) between different input signals (that is, input coming from different sensor modalities). A natural advantage and consequence of self-supervised learning is that it can more easily be performed in an online fashion (given that data can be gathered and labelled without human intervention), where models can be updated or trained completely from scratch. Therefore, self-supervised learning should also be well suited for changing environments, data, and general situations.

Why Self-Supervised Learning?
To apply supervised learning with deep neural networks, we need enough labeled data. To acquire that, human annotators manually label data which is both a time consuming and expensive process. There are also fields such as the medical field where getting enough data is a challenge itself. Thus, a major bottleneck in the current supervised learning paradigm is the label generation part.

Self-supervised Learning is supervised Learning because its goal is to learn a function from pairs of inputs and labeled outputs. Like supervised learning, self-supervised learning has use cases in regression and classification.

Self-supervised learning is like unsupervised Learning because the system learns without using explicitly provided labels. It is different from unsupervised learning because we are not learning the inherent structure of data. Self-supervised learning, unlike unsupervised learning, is not centered around clustering and grouping, dimensionality reduction, recommendation engines, density estimation, or anomaly detection.
Use cases


Using self-supervised learning machines can predict through natural evolution and consequences of its actions, similar to how newborns can learn incredible amounts of information in their first weeks/months of life by observing and being and curious. Self-supervised learning has the potential to scale learning to levels required by new use cases including but not limited to use cases in medicine, autonomous driving, robotics, language understanding, and image recognition. Self-Supervised Learning has found success in multiple fields, for example:
In estimating relative scene depths without human supervision, by using motion segmentation techniques to determine relative depth from geometric constraints between the scene’s motion field and camera motion. In medicine, it has found use cases robotic surgery and in dense depth estimation in monocular endoscopy. In autonomous driving, self-supervised learning is useful for estimating the roughness of the terrain when off-roading.
Conclusion
Self-supervised learning allows us to learn good representations without using large annotated databases. Instead, we can use unlabeled data (which is abundant) and optimize pre-defined pretext tasks. We can then use these features to learn new tasks in which data is scarce.
More on self-supervised learning: Yann LeCun?-?Professor NYU, Chief AI Scientist for Facebook AI Research (FAIR), and Director of AI Research at Facebook. https://venturebeat.com/2020/05/02/yann-lecun-and-yoshua-bengio-self-supervised-learning-is-the-key-to-human-level-intelligence/
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey: https://arxiv.org/abs/1902.06162
Self-Supervised Relative Depth Learning for Urban Scene Understanding: https://arxiv.org/abs/1712.04850
Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy: https://arxiv.org/abs/1806.09521
A Self-Supervised Terrain Roughness Estimator for Off-Road Autonomous Driving: https://arxiv.org/abs/1206.6872
.
But wanna input on few general things, The website design is perfect, the written content is rattling good : D.
Can you be more specific about the content of your article? After reading it, I still have some doubts. Hope you can help me.