
1.Linear Regression
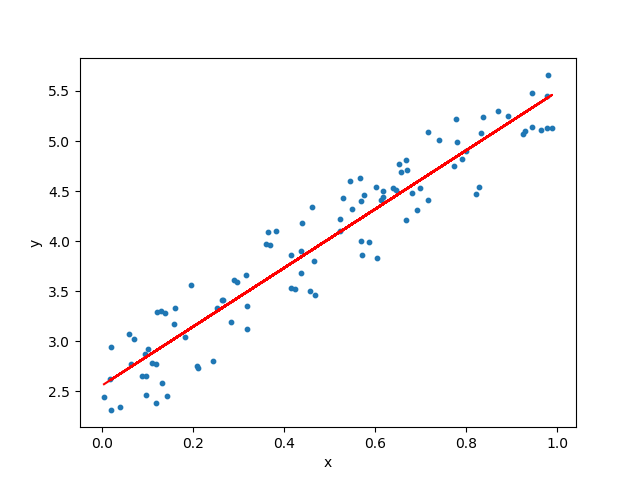
Linear Regression tends to establish a relationship between a dependent variable(Y) and one or more independent variable(X) by finding the best fit of the straight line.
The equation for the Linear model is Y = mX+c, where m is the slope and c is the intercep.
In the diagram, the blue dots we see are the distribution of ‘y’ w.r.t ‘x.’ There is no straight line that runs through all the data points. So, the objective here is to fit the best fit of a straight line that will try to minimize the error between the expected and actual value.
2.Logistic Regression
The logistic regression technique involves the dependent variable, which can be represented in the binary (0 or 1, true or false, yes or no) values, which means that the outcome could only be in either
one form of two. For example, it can be utilized when we need to find the probability of a successful or fail event.

3.Decision Tree
A decision tree is a type of supervised learning algorithm that can be used in classification as well as regressor problems. The input to a decision tree can be both continuous as well as categorical. The
decision tree works on an if-then statement. Decision tree tries to solve a problem by using tree representation (Node and Leaf)
Assumptions while creating a decision tree:
1) Initially all the training set is considered as a root
2) Feature values are preferred to be categorical, if continuous then they are discretized
3) Records are distributed recursively on the basis of attribute values
4) Which attributes are considered to be in root node or internal node is done by using a statistical approach.
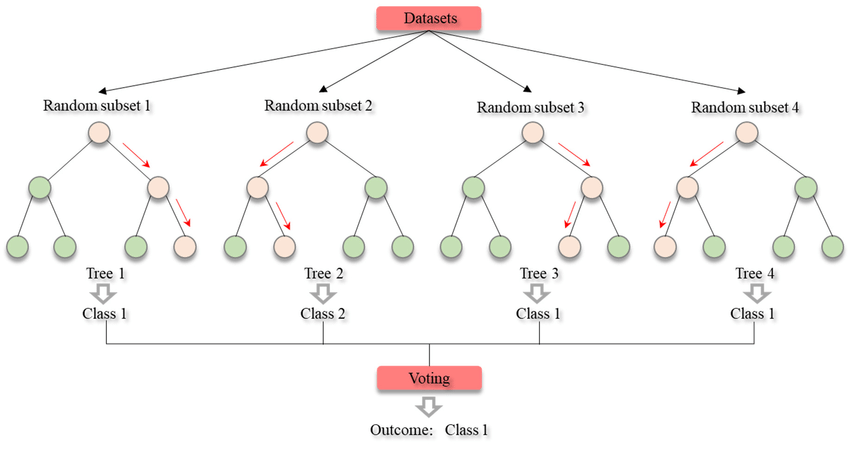
4.Random Forest
Random Forest is an ensemble machine learning algorithm that follows the bagging technique. The base estimators in the random forest are decision trees. Random forest randomly selects a set of
features that are used to decide the best split at each node of the decision tree. Looking at it step-by-step, this is what a random forest model does:
1. Random subsets are created from the original dataset (bootstrapping).
2. At each node in the decision tree, only a random set of features are considered to decide the
best split.
3. A decision tree model is fitted on each of the subsets.
4. The final prediction is calculated by averaging the predictions from all decision trees.
To sum up, the Random forest randomly selects data points and features and builds multiple trees
(Forest).
Random Forest is used for feature importance selection. The attribute (.feature_importances_) is used to find feature importance.
Some Important Parameters:-
1. n_estimators:- It defines the number of decision trees to be created in a random forest.
2. criterion:- “Gini” or “Entropy.”
3. min_samples_split:- Used to define the minimum number of samples required in a leaf node before a split is attempted
4. max_features: -It defines the maximum number of features allowed for the split in each decision tree.
5. n_jobs:- The number of jobs to run in parallel for both fit and predict. Always keep (-1) to use all the cores for parallel processing.
5.Support Vector Machine
A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. After giving an SVM model sets of labeled training data for each category, they’re able to categorize new Data.
Type of svm kernels
1.Linear Kernel
2. Polynomial kernel
3.Gaussian kernel
4. Gaussian radial basis function (RBF)
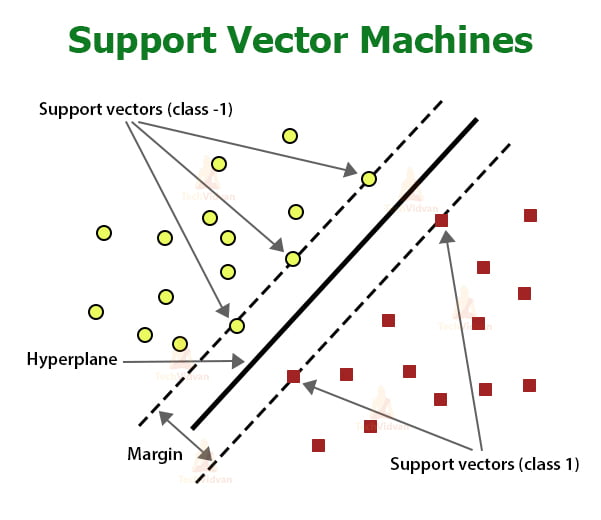
Main Concepts:-
1. Boundary
2. Kernel
3. Support Vector
4. Hyper Plane
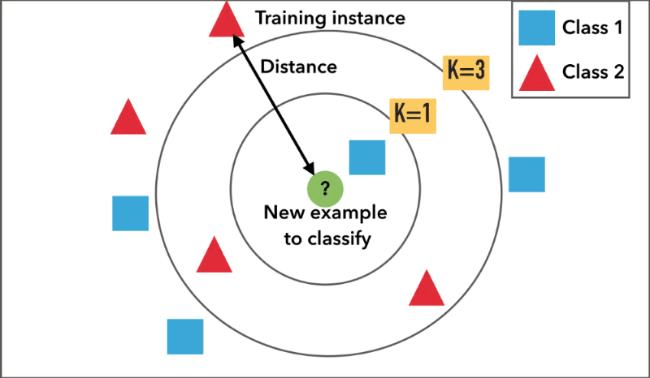
6.K Nearest Neighbor
KNN means K-Nearest Neighbour Algorithm. It can be used for both classification and regression. It is the simplest machine learning algorithm. Also known as lazy learning (why? Because it does not create a generalized model during the time of training, so the testing phase is very important where it does the actual job. Hence Testing is very costly – in terms of time & money). Also called an instancebased or memory-based learning.
In k-NN classification, the output is a class membership. An object is classified by a plurality vote of its neighbors, with the object being assigned to the class most common among its k nearest neighbors (k is
a positive integer, typically small). If k = 1, then the object is assigned to the class of that single nearest neighbor.
7.Naive Bayes Classifier
It is a classification technique based on Bayes‘ Theorem with an assumption of independence among predictors. In simple terms, a Naive Bayes classifier assumes that the presence of a particular feature in a class is unrelated to the presence of any other feature.
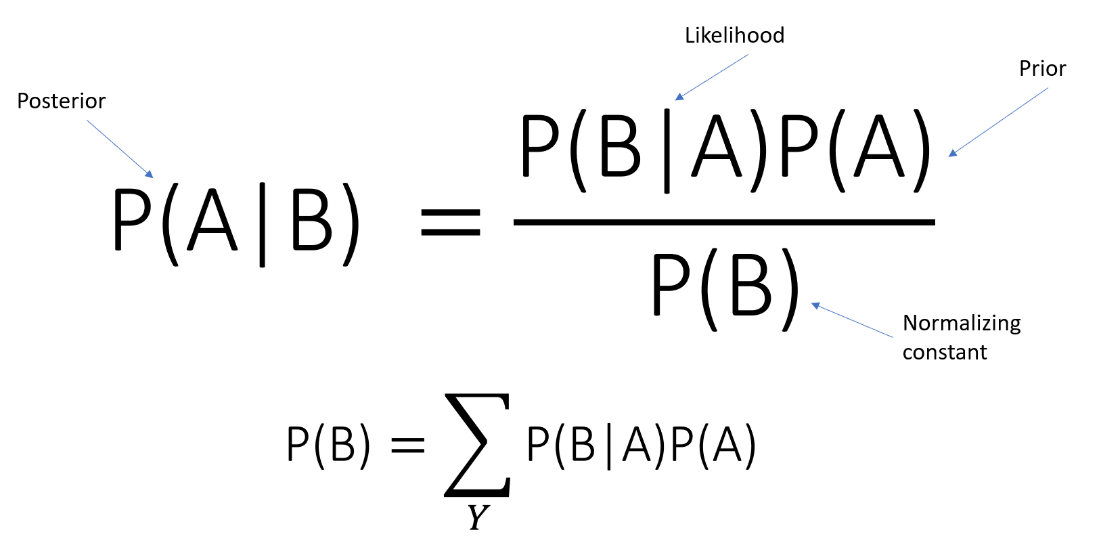
8.XGBoost
XGBoost is a decision-tree-based ensemble Machine Learning algorithm that uses a gradient boosting framework. In prediction problems involving unstructured data (images, text, etc.)
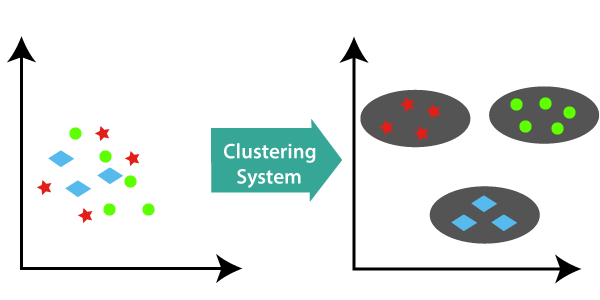
9.Clustring
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups.
Type of Clustring
1.Density-Based Clustering.
2.DBSCAN
3.Hierarchical Clustering.
10.Neural Network
Neural networks are one of the main tools used in machine learning. As neural suggests, they are braininspired systems which are intended to replicate the way that we humans learn. NNs consist of input and output layers, as well as a hidden layer consisting of units that transform the input.

Right away I am going away to do my breakfast, afterward having my breakfast coming again to read additional news.
Hey very nice website!! Guy .. Beautiful ..
Amazing .. I will bookmark your site and take the feeds additionally?
I am satisfied to find a lot of useful information right here in the publish, we need work out more strategies on this regard, thank you for sharing.
. . . . .
Hello! Someone in my Myspace group shared this site with us so I came to give it a look.
I’m definitely loving the information. I’m
bookmarking and will be tweeting this to my followers!
Excellent blog and brilliant design.
Usually I do not read post on blogs, but I would like to say that this write-up very pressured
me to try and do it! Your writing style has been amazed me.
Thanks, quite great post.
Look into my webpage: jasa desain company profile (Chas)
Fascinating blog! Is your theme custom made or did you download it from
somewhere? A design like yours with a few simple tweeks would really make my
blog shine. Please let me know where you got your theme.
Thank you
Spot on with this write-up, I actually feel this amazing site needs a great deal more attention. I’ll probably be returning to read through more, thanks for the info!
That is really attention-grabbing, You’re an excessively skilled
blogger. I have joined your rss feed and look ahead to searching for extra of your great
post. Additionally, I have shared your website in my social networks
Asking questions are truly nice thing if you are not understanding something totally, except
this post provides fastidious understanding even.
Hi there everyone, it’s my first go to see at this website, and piece of writing is
actually fruitful in support of me, keep up posting these types
of articles.
Thanks a bunch for sharing this with all of us you
actually understand what you’re speaking about! Bookmarked.
Kindly additionally seek advice from my website
=). We may have a hyperlink change arrangement between us
Heya i am for the first time here. I found this board and I find It really
useful & it helped me out much. I hope to give something back and aid others like you aided me.
Hi there, I check your blog regularly. Your writing style is
witty, keep doing what you’re doing!
Thanks for finally talking about > Top 10 Machine Learning Algorithms – Buff
ML < Loved it!
Hello, this weekend is fastidious designed
for me, for the reason that this time i am reading
this enormous educational article here at my house.
Hi colleagues, how is all, and what you would like to
say on the topic of this paragraph, in my view its
truly awesome designed for me.
I’m amazed, I have to admit. Rarely do I come across a
blog that’s both educative and amusing, and without
a doubt, you’ve hit the nail on the head. The
issue is something that not enough folks are speaking intelligently
about. I’m very happy that I found this during my search for
something regarding this.
It’s actually a cool and helpful piece of information. I
am glad that you just shared this useful info with us.
Please stay us informed like this. Thanks for sharing.
I’m not sure why but this blog is loading extremely slow
for me. Is anyone else having this problem or is it a problem
on my end? I’ll check back later and see if the problem
still exists.
I got this web page from my friend who told me about this
web site and at the moment this time I am browsing this website and
reading very informative content at this place.
Right here is the perfect webpage for anyone who would
like to understand this topic. You understand so much its almost tough to argue with you (not that I actually
would want to…HaHa). You certainly put a new spin on a subject that’s been discussed for many years.
Excellent stuff, just excellent!
This piece of writing presents clear idea in favor of the new people of blogging, that
truly how to do blogging.
Here is my blog – science theory
Its like you read my mind! You appear to know so much about this,
like you wrote the book in it or something. I think that you can do with
some pics to drive the message home a little bit, but instead of that, this is wonderful blog.
An excellent read. I’ll definitely be back.
I am extremely inspired along with your writing talents as
well as with the layout on your blog. Is this a
paid subject matter or did you customize it your self?
Either way keep up the excellent high quality writing, it is
rare to look a great weblog like this one nowadays..
I love your blog.. very nice colors & theme. Did you create this website yourself or did you hire someone
to do it for you? Plz respond as I’m looking to construct my own blog and
would like to find out where u got this from. thanks
It’s awesome to go to see this site and reading the views of
all colleagues regarding this paragraph, while I am also
eager of getting experience.
I think this is among the most important information for me.
And i am glad reading your article. But wanna remark on some
general things, The site style is wonderful, the articles is really
excellent : D. Good job, cheers
Hey I know this is off topic but I was wondering if you knew of any
widgets I could add to my blog that automatically tweet my newest twitter updates.
I’ve been looking for a plug-in like this for quite some time and was hoping maybe you
would have some experience with something like this. Please let me know if you run into anything.
I truly enjoy reading your blog and I look forward to your
new updates.
Your means of describing all in this piece of writing is
in fact pleasant, every one be capable of without difficulty understand it,
Thanks a lot.
Hi, i think that i noticed you visited my site so
i got here to return the choose?.I am trying
to to find things to enhance my web site!I suppose its adequate to use a few of your concepts!!
Hey very nice web site!! Man .. Excellent .. Amazing .. I’ll bookmark your site and take the feeds also…I’m happy to find a lot of useful info here in the post, we need work out more strategies in this regard, thanks for sharing. . . . . .