
What is OCR?
OCR is one of the well-known computer vision techniques that is used to extract text from an image.

Lets take an Example.
Have you ever broken a traffic rule? Uncool, but you must have gotten an online challan of the fine you
need to pay. The way the traffic department recognizes your number plate is by the use of OCR.

A brief history of OCR:
- It is one of the earliest addressed computer vision tasks.
- Since in some aspects it does not require deep learning, there were different implementations even before the deep learning boom in 2012, and some even dated back to 1914.
- On the eve of the First World War, physicist Emanuel Goldberg invented a machine that could read characters and convert them into telegraph code. In the 1920s, he went a step further and created the first electronic document retrieval system.
- Modern OCR makes use of deep learning as the use cases of OCR have grown and have become generalized.
General process of OCR:
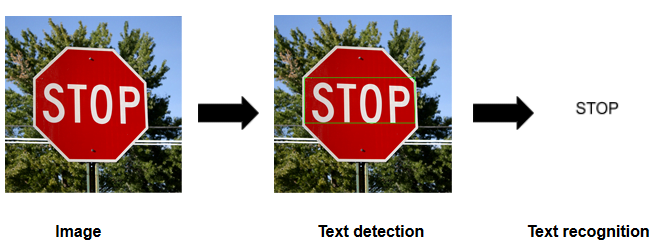
OCR projects have 3 main high level tasks.
- Loading the image and preprocessing.
- Text detection.
- Text recognition.
The preprocessing:
The images come in a wide variety of types. We need to preprocess the images for our text detection model to detect the text accurately. Following preprocessing is recommended
Binarization:
- A colored image is converted to black and white.
- Done by fixing a threshold eg. 127.
- A pixel value greater than the threshold is considered as a white pixel otherwise it is a black pixel.
Skew Correction:
- While scanning a document, it might be slightly skewed. It is important to correct the skew before feeding the document to our detection model.
Noise Removal:
- The main objective of the Noise removal stage is to smoothen the image by removing small dots/patches which have high intensity than the rest of the image.
Thinning and Skeletonization :
- Performed for handwritten text to generalize as everyone has a different style of writing.
Text detection and recognition:
- The most common way to detect text from an image is to use the OpenCV library for python. For recognition of text, the most popular library is PyTesseract which lets us convert image to a string.
The steps are :
- Use OpenCV contours detection to detect contours to extract chunks of data:
contours, _ = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
- Use the contours to find coordinates of text. Crop image with respect to the coordinates and use pytesseract to convert the text to string.
for cnt in contours:
x, y, w, h = cv2.boundingRect(cnt)
# Drawing a rectangle on copied image
rect = cv2.rectangle(image, (x, y), (x + w, y + h), (0,
255, 255), 2)
# Cropping the text block for giving input to OCR
cropped = image[y:y + h, x:x + w]
# Using pytesseract to convert cropped image to
text
config = ('-l eng --oem 1 --psm 3')
text = pytesseract.image_to_string(cropped,
config=config)
print(text)
Applications of OCR:
- Data entry for business documents.
- Auto grading of MCQ papers.
- Analyzing healthcare reports.
- Number plate detection.
- Traffic sign recognition.
- Baggage handling at airports.