
LINEAR REGRESSION
- The ultimate goal of linear regression is to find a line that best fits the data.
- The goal of multiple linear regression and polynomial regression is to find the plane that best fits the data in n-dimension.
LOGISTIC REGRESSION
- Logistic regression is used to describe data and to explain the relationship between one dependent binary variable and one or more independent variables.
- The logistic equation is created in such a way that the output a probability value that can be mapped to classes and values can only be between 0 and 1.
SUPPORT VECTOR MACHINE
- SVM finds the hyperplane between classes of data which maximizes the margin between classes.
- There can be many hyperplanes that can separate the classes. but only one plane can maximize the distance between the classes.
K NEAREST NEIGHBOR
- K nearest neighbors is a simple algorithm that stores all available cases and classifies new cases based on a similarity measure.
- It is an approach to data classification that estimates how likely a data point is to be a member of one group or the other depending on what group the data points nearest to it are in.
NAIVE BAYES
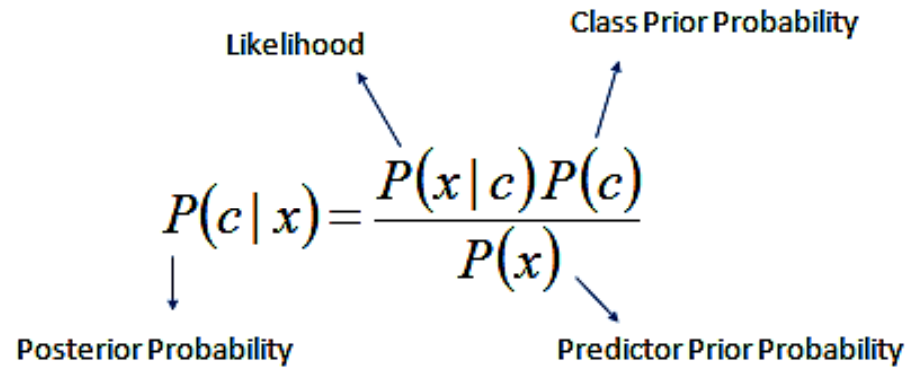
- Naive Bayes is another popular classification algorithm.
- The goal is to find the class with the maximum proportional probability.
- It answers the following question. “What is the probability of A given B? And because of the naive assumption that variables are independent given the class
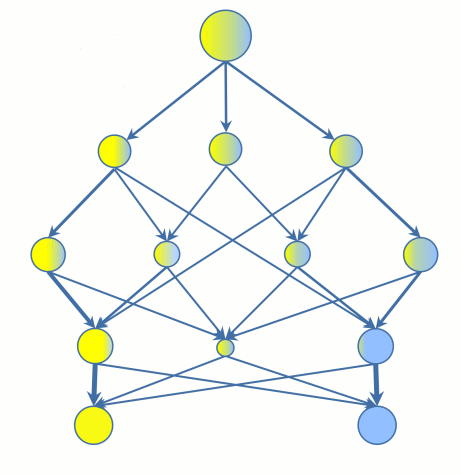
DECISION TREES
- Each circle above is called a node.
- The last nodes of the decision tree, where a decision is made, are called the leaves of the tree.
- Decision trees are intuitive and easy to build but fall short when it comes to accuracy.
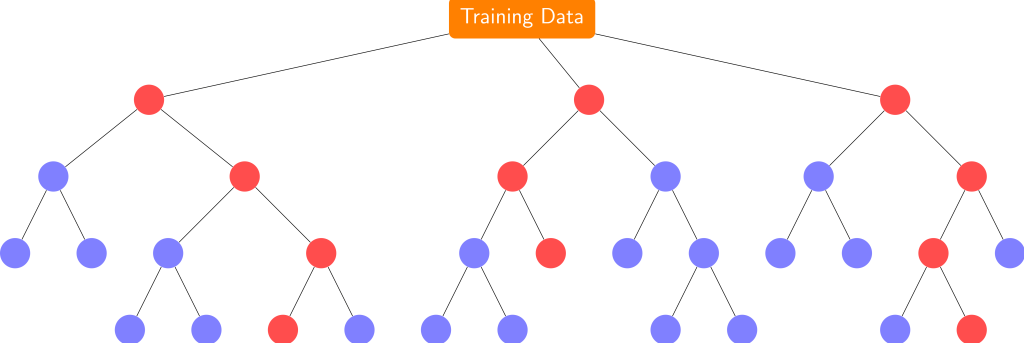
RANDOM FOREST
- It creates multiple decision trees using bootstrapped datasets of the original data and randomly selecting a subset of variables at each step of the decision tree.
- The model then selects the mode of all of the predictions of each decision tree.
- By multiple trees it reduces the risk of error from an individual tree.
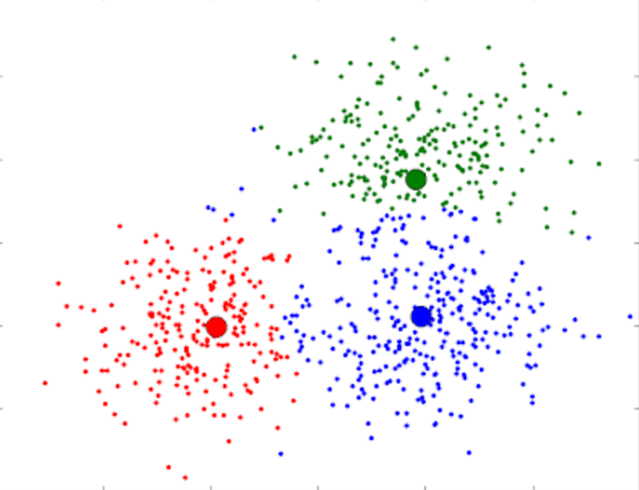
CLUSTERING
- Clustering is an unsupervised technique that involves the grouping, or clustering, of data points. It’s frequently used for customer segmentation, fraud detection, and document classification.
- Common clustering techniques include k-means clustering, hierarchical clustering, mean shift clustering, and density-based clustering. While each technique has a different method in finding clusters, they all aim to achieve the same thing.
After reading this blog, I am sure you will get the basics concepts of the machine learning model.
Amazing! Its actually awesome piece of writing,
I have got much clear idea on the topic of from this article.
Wow that was strange. I just wrote an really long comment but after I clicked
submit my comment didn’t show up. Grrrr… well I’m not writing all
that over again. Anyhow, just wanted to say great blog!
I am sure this article has touched all the internet users, its really really fastidious piece of
writing on building up new blog.
You really make it seem really easy together with your presentation however I in finding this topicto be really something that I believe I’d never understand.It kind of feels too complex and very wide for me.I’m taking a look forward for your next put up, I will attempt to get the cling of it!
Paragraph writing is also a excitement, if you be acquainted with after that you can write if
not it is complicated to write.
Sweet blog! I found it while surfing around on Yahoo News.
Do you have any suggestions on how to get listed in Yahoo News?
I’ve been trying for a while but I never seem to get there!
Thank you
Hi! This post could not be written any better! Reading
this post reminds me of my good old room mate! He always kept talking about this.
I will forward this page to him. Fairly certain he will have a
good read. Many thanks for sharing!
Thanks for sharing your thoughts on website. Regards
It’s awesome for me to have a website, which is beneficial
designed for my experience. thanks admin
Good write-up, I am regular visitor of one¦s website, maintain up the nice operate, and It’s going to be a regular visitor for a long time.
Great wordpress blog here.. It’s hard to find quality writing like yours these days. I really appreciate people like you! take care
The articles you write help me a lot and I like the topic
Thanks for posting such an excellent article. It helped me a lot and I love the subject matter.
I want to thank you for your assistance and this post. It’s been great.
You’ve been great to me. Thank you!
You’ve been great to me. Thank you!
Your articles are extremely helpful to me. Please provide more information!
Thank you for being of assistance to me. I really loved this article.
Thanks for writing this article. I enjoy the topic too.
whoah this blog is magnificent i love reading your posts. Keep up the good work! You know, many people are searching around for this information, you could aid them greatly.
Spot on with this write-up, I actually feel this web site needs much more attention. I’ll probably be returning to see more, thanks for the advice!
These are actually great ideas in on the topic of blogging.
You have touched some fastidious things here. Any way keep up
wrinting.
Simply desire to say your article is as astonishing. The clarity in your post is simply cool and i could assume you are an expert on this subject. Well with your permission let me to grab your RSS feed to keep updated with forthcoming post. Thanks a million and please keep up the gratifying work.
As I web-site possessor I believe the content matter here is rattling magnificent , appreciate it for your efforts. You should keep it up forever! Good Luck.
Everyone loves it when people come together and share ideas. Great site, continue the good work.