
YOLO (You only look once) is the state-of-the-art, real-time system built on deep learning for solving object detection problems.
YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance.

YOLO (You Only Look Once) real-time object detection algorithm, which is one of the most effective object detection algorithms that also encompasses many of the most innovative ideas coming out of the computer vision research community. Object detection is a critical capability of autonomous vehicle technology. It’s an area of computer vision that’s exploding and working so much better than just a few years ago. At the end of this article, we’ll see a couple of recent updates to YOLO by the original researchers of this important technique.

As shown in the first image on the above first one, the algorithm first divides the image into defined bounding boxes then runs a recognition algorithm in parallel for all of these to identify which object class they belong to, lastly, it goes on to merging these boxes intelligently to form optimal bounding boxes around the objects.

YOLO looks at the whole image at test time so its redictions are informed by the global context in the image.

Previous methods, like R-CNN and its variations, used a pipeline to perform this task in multiple steps. This can
be slow to run and also hard to optimize because each individual component must be trained separately. YOLO
does it all with a single neural network.
The Training:
The authors describe the training in the following way:
- First, pretrain the first 20 convolutional layers using the ImageNet 1000-class competition dataset, using an input size of 224×224.
- Then, increase the input resolution to 448×448.
- Train the full network for about 135 epochs using a batch size of 64, momentum of 0.9 and decay of 0.0005.
- Learning rate schedule: for the first epochs, the learning rate was slowly raised from 0.001 to 0.01. Train for about 75 epochs and then start decreasing it.
- Use data augmentation with random scaling and translations, and randomly adjusting exposure and saturation.
The loss:
YOLO predicts multiple bounding boxes per grid cell. To compute the loss for the true positive, we only want one of them to be responsible for the object. For this purpose, we select the one with the highest IoU (intersection over union) with the ground truth.
Each prediction gets better at predicting certain sizes and aspect ratios. YOLO uses sum-squared error between the predictions and the ground truth to calculate the loss.
The loss function composes of:
- the classification loss.
- the localization loss (errors between the predicted boundary box and the ground truth).
- the confidence loss (the objectness of the box).
The loss function:
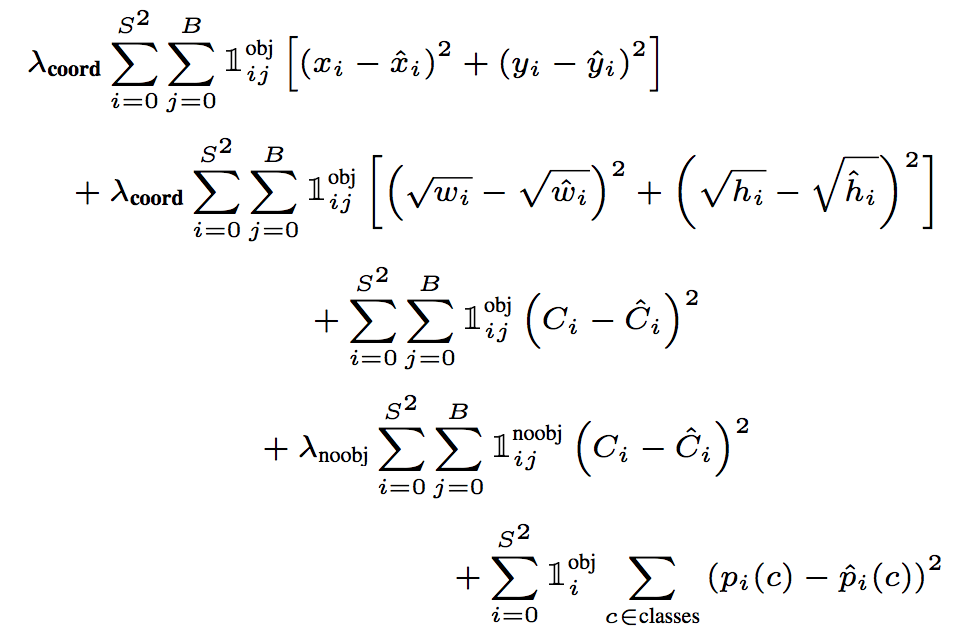
Code:
First download coco labels and yolov3 cfg file:
https://github.com/noumannahmad/ComputerVision/tree/master/Yolo_Object_Detection/yolo-coco
1. coco.names
2. yolov3.cfg
Download weights: https://pjreddie.com/media/files/yolov3.weights
YOLO FOR object detction using image as input
# import the necessary packages
import numpy as np
import argparse
import time
import cv2
import os
# construct the argument parse and parse the arguments
yolo_path='yolo-coco'
# load the COCO class labels our YOLO model was trained on
labelsPath =(yolo_path+"/coco.names")
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the YOLO weights and model configuration
weightsPath = (yolo_path+"/yolov3.weights")
configPath = (yolo_path+"/yolov3.cfg")
# load our YOLO object detector trained on COCO dataset (80 classes)
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
# load our input image and grab its spatial dimensions
image = cv2.imread('aluterus_scriptus_1.jpg')
(H, W) = image.shape[:2]
# determine only the *output* layer names that we need from YOLO
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# construct a blob from the input image and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes and
# associated probabilities
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
# show timing information on YOLO
print("[INFO] YOLO took {:.6f} seconds".format(end - start))
# initialize our lists of detected bounding boxes, confidences, and class IDs, respectively
boxes = []
confidences = []
classIDs = []
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability) of
# the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > 0.5:
# scale the bounding box coordinates back relative to the
# size of the image, keeping in mind that YOLO actually
# returns the center (x, y)-coordinates of the bounding
# box followed by the boxes' width and height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top and
# and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates, confidences,
# and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# apply non-maxima suppression to suppress weak, overlapping bounding
# boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.3)
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# draw a bounding box rectangle and label on the image
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(image, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]], confidences[i])
cv2.putText(image, text, (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX,
0.5, color, 2)
# show the output image
cv2.imshow("Image", image)
cv2.waitKey(0)
YOLO FOR object detction using vide or real time as input
# import the necessary packages
import numpy as np
import imutils
import time
import cv2
# construct the argument parse and parse the arguments
yolo_path='yolo-coco'
# load the COCO class labels our YOLO model was trained on
labelsPath =(yolo_path+"/coco.names")
LABELS = open(labelsPath).read().strip().split("\n")
# initialize a list of colors to represent each possible class label
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(LABELS), 3),
dtype="uint8")
# derive the paths to the YOLO weights and model configuration
weightsPath = (yolo_path+"/yolov3.weights")
configPath = (yolo_path+"/yolov3.cfg")
# load our YOLO object detector trained on COCO dataset (80 classes)
# and determine only the *output* layer names that we need from YOLO
print("[INFO] loading YOLO from disk...")
net = cv2.dnn.readNetFromDarknet(configPath, weightsPath)
ln = net.getLayerNames()
ln = [ln[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# initialize the video stream, pointer to output video file, and
# frame dimensions
vs = cv2.VideoCapture(0)
(W, H) = (None, None)
# try to determine the total number of frames in the video file
try:
prop = cv2.cv.CV_CAP_PROP_FRAME_COUNT if imutils.is_cv2() \
else cv2.CAP_PROP_FRAME_COUNT
total = int(vs.get(prop))
print("[INFO] {} total frames in video".format(total))
# an error occurred while trying to determine the total
# number of frames in the video file
except:
print("[INFO] could not determine # of frames in video")
print("[INFO] no approx. completion time can be provided")
total = -1
# loop over frames from the video file stream
while True:
# read the next frame from the file
(grabbed, frame) = vs.read()
# if the frame was not grabbed, then we have reached the end
# of the stream
if not grabbed:
break
# if the frame dimensions are empty, grab them
if W is None or H is None:
(H, W) = frame.shape[:2]
# construct a blob from the input frame and then perform a forward
# pass of the YOLO object detector, giving us our bounding boxes
# and associated probabilities
blob = cv2.dnn.blobFromImage(frame, 1 / 255.0, (416, 416),
swapRB=True, crop=False)
net.setInput(blob)
start = time.time()
layerOutputs = net.forward(ln)
end = time.time()
# initialize our lists of detected bounding boxes, confidences,
# and class IDs, respectively
boxes = []
confidences = []
classIDs = []
# loop over each of the layer outputs
for output in layerOutputs:
# loop over each of the detections
for detection in output:
# extract the class ID and confidence (i.e., probability)
# of the current object detection
scores = detection[5:]
classID = np.argmax(scores)
confidence = scores[classID]
# filter out weak predictions by ensuring the detected
# probability is greater than the minimum probability
if confidence > 0.5:
# scale the bounding box coordinates back relative to
# the size of the image, keeping in mind that YOLO
# actually returns the center (x, y)-coordinates of
# the bounding box followed by the boxes' width and
# height
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# use the center (x, y)-coordinates to derive the top
# and and left corner of the bounding box
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# update our list of bounding box coordinates,
# confidences, and class IDs
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# apply non-maxima suppression to suppress weak, overlapping
# bounding boxes
idxs = cv2.dnn.NMSBoxes(boxes, confidences, 0.5,
0.3)
# ensure at least one detection exists
if len(idxs) > 0:
# loop over the indexes we are keeping
for i in idxs.flatten():
# extract the bounding box coordinates
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
# draw a bounding box rectangle and label on the frame
color = [int(c) for c in COLORS[classIDs[i]]]
cv2.rectangle(frame, (x, y), (x + w, y + h), color, 2)
text = "{}: {:.4f}".format(LABELS[classIDs[i]],
confidences[i])
cv2.putText(frame, text, (x, y - 5),cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
frameresize=cv2.resize(frame,(960,520))
cv2.imshow("Application", frameresize)
key = cv2.waitKey(1)
if key == ord('q'):
break
# release the file pointers
cv2.destroyAllWindows()
vs.release()
More read: https://arxiv.org/abs/1506.02640
Woh I love your content, saved to my bookmarks! .
I haven’t checked in here for some time since I thought it was getting boring, but the last few posts are good quality so I guess I’ll add you back to my daily bloglist. You deserve it my friend 🙂